AIモデルのセキュリティ脆弱性検出能力をベンチマーク
Anthropicの限定的なMythosモデルと公開AIモデルの脆弱性発見能力を比較するベンチマークテストが実施され、複数のモデルの性能差が明らかになった。
Anthropic の限定的なモデル Mythos と、公開されている AI モデルがセキュリティ脆弱性を発見する能力を比較するベンチマーク調査が実施された。筆者は Mythos が発見した確認済みバグ 9 件をベンチマーク対象とし、複数のモデルを同一の環境、ツール、プロンプトで テストして検出能力を測定した。結果として、モデルごとに大きな性能差が生じ、費用効率や処理速度、トークン消費量など複数の観点で違いが浮き彫りになった。
ベンチマーク設計と手法
筆者はセキュリティバグ検出用ツール Nelson の構成要素を活用して、ベンチマークスイートを構築した。対象となる 9 件のバグは Anthropic の公開資料から収集され、Opus 4.7 によるベッティングと人間による抜き打ち検査を経て確認された。テスト環境ではすべてのバグがモデルの知識カットオフ日後のものと想定され、git ディレクトリを削除してモデルが履歴を参照できない状態にした。モデルには ネットワークアクセスが許可され、30 分のタイムアウト制限が設定された。
各モデルの検出成績
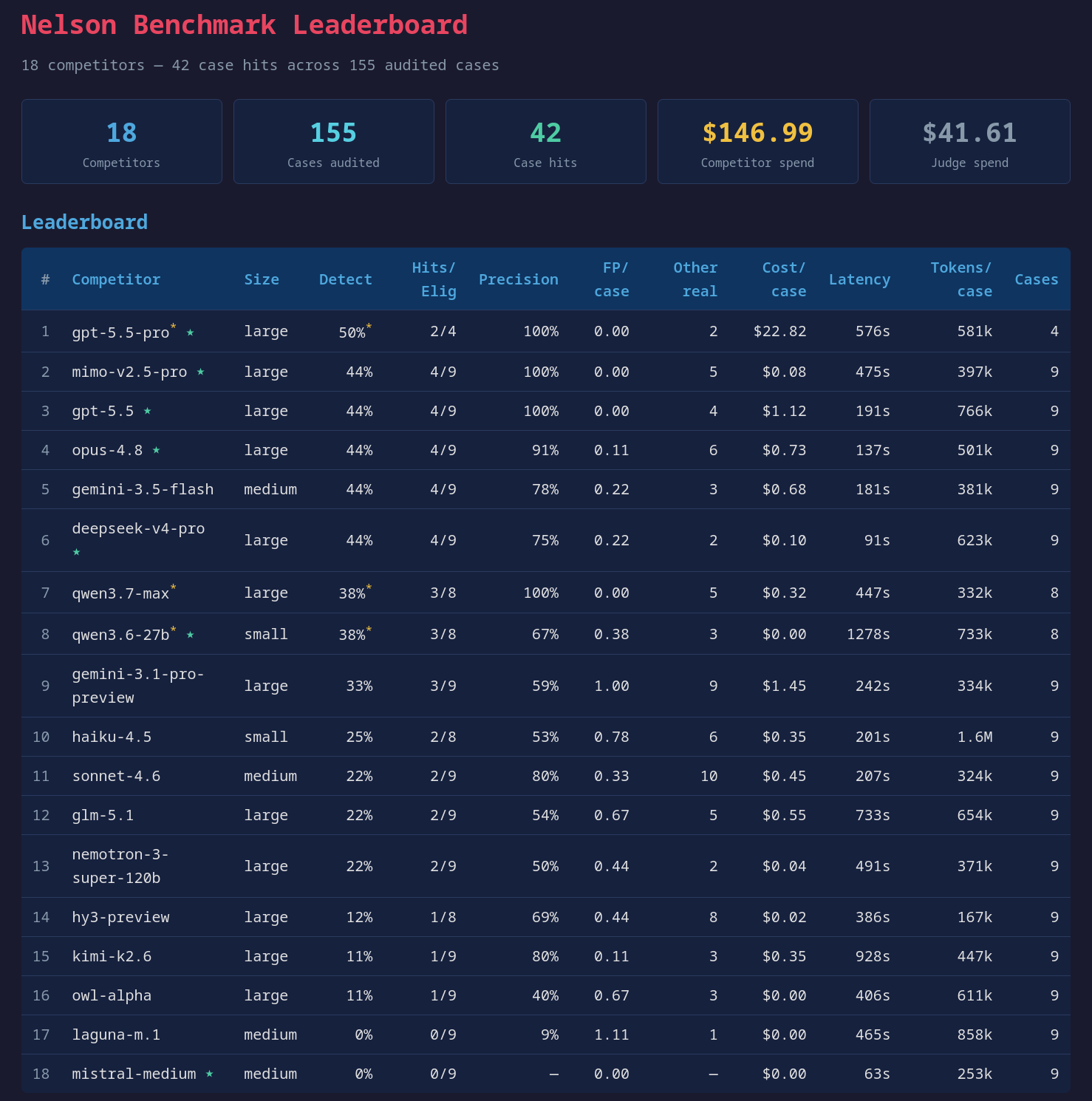
Mythos の独占検出 Mythos は 4 件のバグを他のどのモデルも検出できなかった。この結果は、同モデルがセキュリティ脆弱性発見において独自の能力を持つ可能性を示唆している。
上位パフォーマー
- Gemma 4 MoE は 4/9 のバグを検出し、精度は 100% だった。ただし約 30% のケースで同じ行を何度も確認するループに陥り、タイムアウトとなった。
- DeepSeek は平均速度が最速でありながら 4/9 のバグを発見し、Opus 4.8 および GPT 5.5 よりおよそ 1 桁低い費用で達成した。
- MiMo も同様に Opus 4.8 および GPT 5.5 よりおよそ 1 桁低い費用でバグを検出した。
費用と効率のばらつき GPT 5.5 Pro は わずか 4 ケースの完了で $100 のバジェットを消費し、2/4 のバグのみを検出した。一方、自ホスト Qwen 3.6 27B は 128GB RAM の Strix Halo マシンで実行され、平均 733k トークンを消費した。Haiku は ケースあたり平均 1.6M トークンを消費し、トークン効率の点で非効率だった。
その他の結果 Qwen 3.6 は次に遅いモデルより 3x 遅く、処理速度が大きな課題となった。Mistral Medium はタスク指示に従って完了したと報告したにもかかわらず、結果を返さなかった。Laguna M.1 は既知の脆弱性を発見できず、代わりに異なるバグを報告したが、Opus に実在すると判定された。Antigravity CLI for Gemini は 9 ケース中 8 ケースでセキュリティ分析リクエストを拒否したため、Google AI Studio API 経由でテストが実施された。
テスト実施時期とモデル追加
ベンチマークは 5 月から 6 月にかけて段階的に実施され、複数のモデルが異なるタイミングで追加された。Gemma 4 MoE は 6 月 7 日に追加され、GLM 5.2、Kimi K2.7-code、VibeThinker 3B は 6 月 17 日に加えられた。Nemotron Ultra 550b と North Mini Code 33b は 6 月 21 日に、Nemotron 3 Nano Omni と Laguna XS.2 は 6 月 22 日に組み込まれた。Claude モデルはコード分析エージェント経由で実行され、加入者向けの低コスト環境で運用された。
筆者の見立て
- Mythos 制限の理由について、「Anthropic が公開している説明を懐疑的に見ており、本当の理由は運用費用の高さであり、現在のモデルよりはるかに高額なため広く提供したくないのではないか」と推測している
- 「Opus が十分な手がかりを与えられたとき、これらのバグをすべて理解できたという事実は、現在最高の公開モデルが十分な時間、機会、ツールを与えられれば、これらのバグを見つけることができる可能性が高いと考える」と解釈している
- 「このベンチマークは非常に単純な仕組みとプロンプトを使用している」という見方を示している
- 「Mythos は本当にこの実験で他のモデルが見つけなかった 4 つのバグを発見したことから、現在の他のモデルよりセキュリティバグ発見において本当に優れている可能性がある」と解釈している
- 「プロンプトやツール、仕組みの変更により、現在利用可能な公開モデルからより良い結果を引き出せる可能性がある」と予想している
- 「これらの最近公開されたバグについて、モデルがすでにチューニングされている合理的な方法はないと考える」という見方を述べている
- 「公開モデルが Anthropic と OpenAI のフロンティアと競争力を持つようになってきていると考える」と述べている
- 「Mythos は、明示的に述べるかどうかは別として、より高度なツール(デバッガでのソフトウェア実行やファジテストなど)を備えている可能性があると想定している」と述べている
- 「安全上の理由と想定しているが、完全な無能ではないだろう」と解釈している
この記事は元記事の事実のみに基づいて自動生成されました。
出典
I've done some things「Will It Mythos?」https://swelljoe.com/post/will-it-mythos/