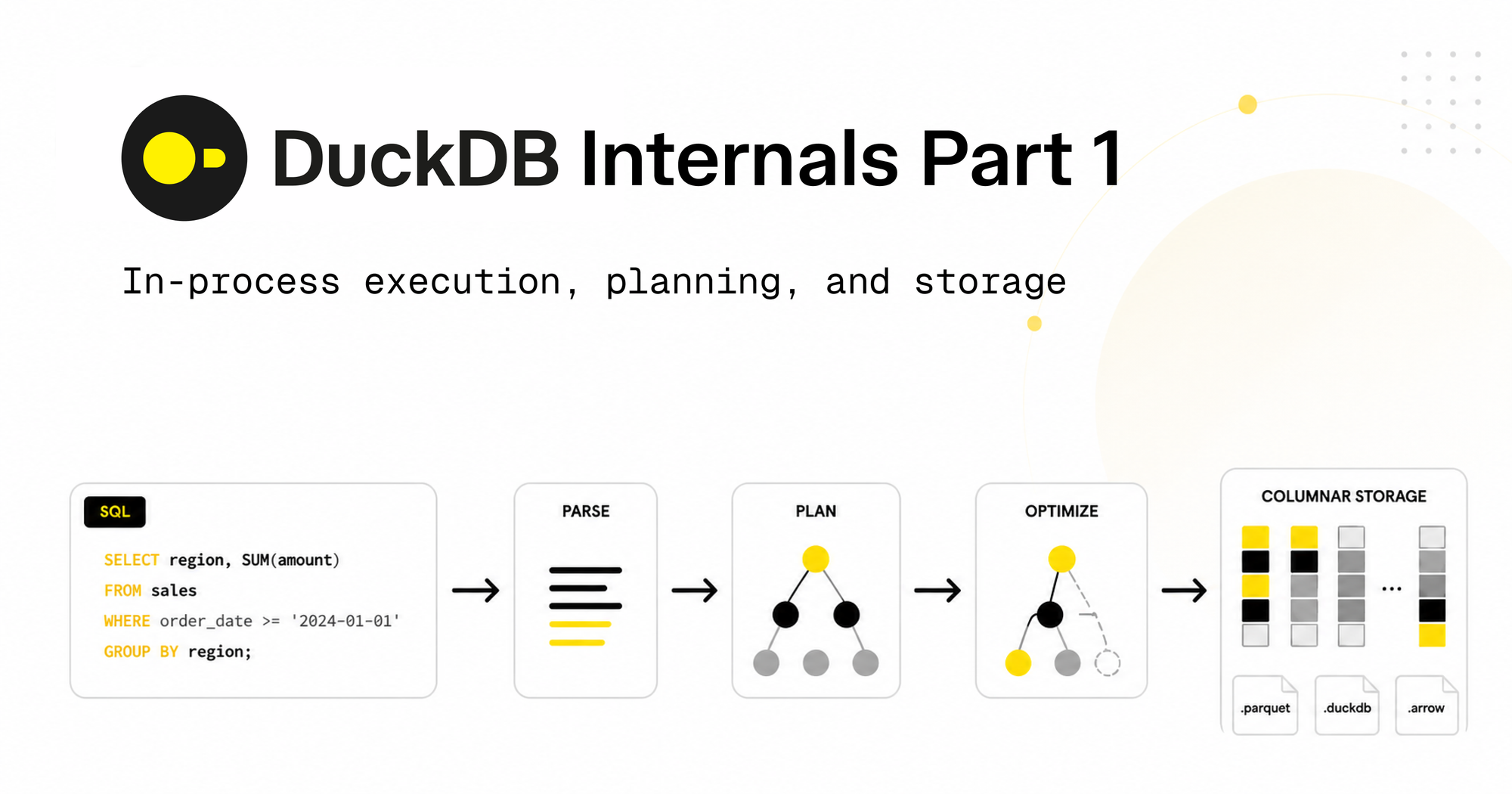
DuckDB が高速である理由:アーキテクチャと設計の深掘り
2019年にCWI Amsterdamで開始された研究プロジェクトから、DuckDBは現在最も採用されているデータベースの一つへと成長した。本記事は、DuckDBの内部構造と性能最適化について3部構成で解説する第1部である。
DuckDB は、インプロセスな分析型SQL データベースであり、20 MB以下の単一バイナリとして提供される外部依存関係がない。DuckDB は Parquet、CSV、JSON ファイルのディレクトリをSQL データベースのように扱うことができ、単一ノード分析エンジンの中で最速の部類に入る。同社の高速性の背景には、インプロセス実行、カラムナ圧縮ストレージとゾーンマップ、ベクトル化実行、モーセル駆動並列化、スナップショット分離を備えた楽観的MVCC など複数の設計選択が挙げられるとみられる。
SQL解析と最適化パイプライン
DuckDB は Postgres パーサーのフォークを使用して SQL を抽象構文木(AST)に変換する。バインディングプロセスでは、AST 内のすべての名前をカタログに照らし合わせて解決される。その後、オプティマイザが33個の小規模で焦点を絞った変換の連鎖として機能し、フィルタプッシュダウン、相関サブクエリのアンネスト、ハッシュジョイン中の動的ジョイン フィルタプッシュダウンが実装されている。ジョイン順序最適化には動的計画法(DPhyp または DPccp)が用いられ、6つのテーブルをジョインする場合でも30,240個の可能なツリー形状の中から最適な順序を見つける。最適化フェーズは通常約1ミリ秒で完了する。

ストレージとカラムナアーキテクチャ
DuckDB のデフォルトブロックサイズは256 KBで、16 KBまで設定可能であり、各ブロックはチェックサムを保持している。カラムはDuckDB内で個別に保存され、行グループは最大122,880行を含む。各行グループには、最小値・最大値およびヌル数を保持するゾーンマップが付属する。Parquet形式もカラムナ形式であり、行グループごとに最小値・最大値統計を含む。
リモートから Parquet をクエリする際、DuckDB はフッターと必要な行グループおよびカラムチャンクのみを読み込む。「WHERE event_date > '2026-01-01'」のような述語でスキャンを実行する場合、DuckDB は各行グループの最大値をチェックしてからそのデータを読み込むかどうかを判断する。ゾーンマップの有効性は列の順序に大きく依存し、ソート済み列は行グループあたりの最小値・最大値の範囲が狭い一方、分散した値はより効果的でない範囲をもたらすとみられる。
ベクトル化実行と並列化
DuckDB のチャンクサイズは2,048行のバッチである。物理計画はパイプラインに分割され、パイプラインは各CPUコアが入力スライスの独自のコピーで独自のアセンブリラインを実行できるため、きれいに並列化されるとみられる。DuckDB の並列化はローカルであり、全体的なクエリの全体的並列化を計画するのではなく、一度に1つのパイプラインを並列化する。
データ形式と統合
CSV スニッファーは方言、列型、ヘッダー行を検出する。一方、MotherDuck、Hex、Omni、Evidence、Fivetran、Rill など、DuckDB を搭載した製品を構築している企業がある。Greybeam は DuckDB を使用して BI および分析ワークロード向けに数百万のクエリを実行している。
DuckDB は、NumPy バッファを直接読み込む場合、DuckDB が同じ物理レイアウトを理解しているため、ゼロコピーアクセスが可能なとき、Python プロセスが既に所有している基礎となるバッファを読み込むことができるが、これはデータフレームの物理レイアウト、列型、ヌル表現、文字列ストレージに依存する。
ブロックレベルのチェックサミングは、クラウドデータウェアハウスよりもデータ破損に対する保護が少ないノートパソコンやエッジデバイスなどのコンシューマーハードウェア向けの有用なバックストップとみられる。
筆者の見立て
- DuckDB の高速性は、インプロセス実行、カラムナ圧縮ストレージとゾーンマップ、ベクトル化実行、モーセル駆動並列化、スナップショット分離を備えた楽観的MVCC といった複数の設計選択に起因すると解釈している。
- NumPy バッファから直接アクセスする場合のゼロコピー実装は、DuckDB が同じ物理レイアウトを理解していることを示唆している。
- パイプラインの並列化は、各 CPU コアが入力スライスの独自のコピーで実行できるため、きれいに並列化できると解釈している。
- DuckDB の並列化戦略は、全体的なクエリ計画ではなく、一度に1つのパイプラインを並列化する方式を採用していると論じている。
- チェックサミングは、クラウド環境よりもデータ破損リスクが高いコンシューマーハードウェアに対する保護として機能する可能性を示唆している。
- ゾーンマップの効率は列の並べ替え方法に大きく依存し、ソート済み列では最小値・最大値の範囲が狭く、分散した値では効率が低下する可能性があると論じている。
この記事は元記事の事実のみに基づいて自動生成されました。
出典
Greybeam、「DuckDB Internals: Why is DuckDB Fast? (Part 1)」、https://www.greybeam.ai/blog/duckdb-internals-part-1