大規模言語モデルの内部動作メカニズム
現代のLLMはトランスフォーマーブロックを積み重ねた構造により機能し、トークン化から注意機構、フィードフォワードネットワークに至るまで、複数の段階を経て次のトークンを予測している。
Vaswani et al.の2017年の原論文以来、トランスフォーマーアーキテクチャは大規模言語モデルの基盤となっている。0xkatoの記事では、トークン化からロジット予測に至るまでの各段階における具体的な仕組みが詳説されている。
トークン化と埋め込み
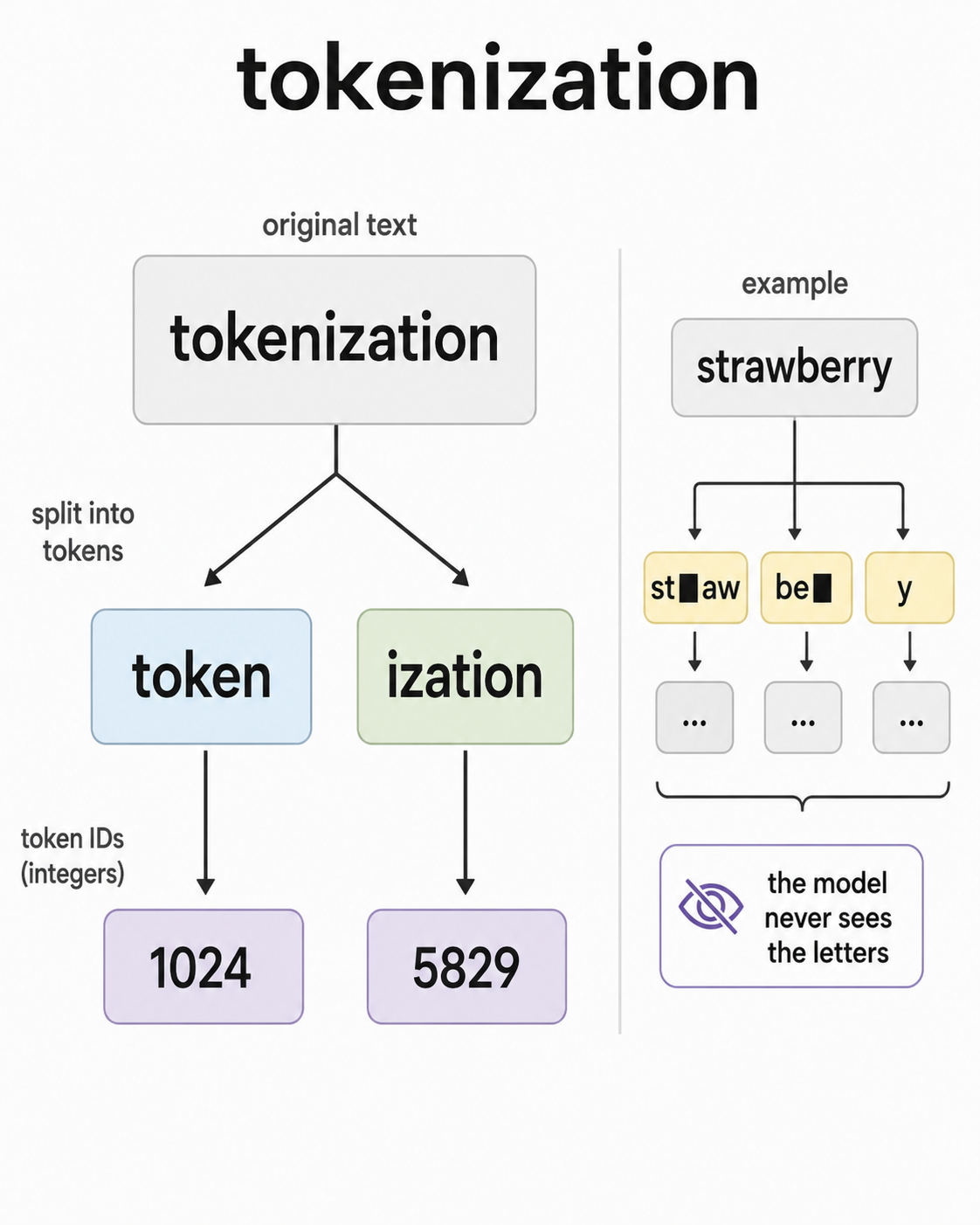
現代のLLMは異なるトークナイザーを採用しており、GPTモデルはバイトペア符号化(BPE)の変種を使用し、LLaMAスタイルのモデルではSentencePieceが一般的である。すべてのモデルは語彙の各エントリに対応する埋め込み行列を有し、これは数万から数十万のエントリを含む。埋め込み空間では「king」のベクトルは「queen」に近く、「Paris」は「France」に近いなど、意味的な構造が自然に形成されている。
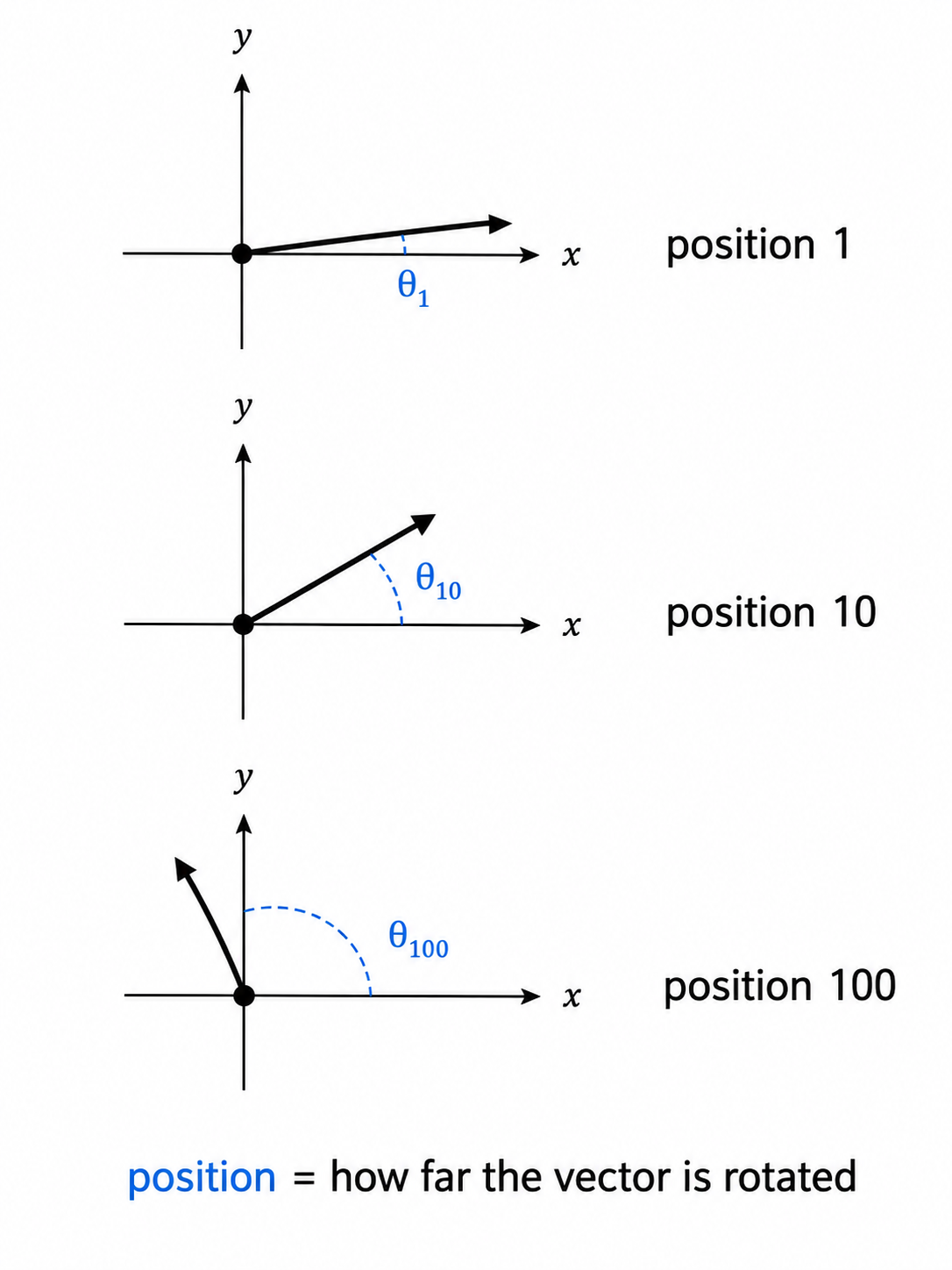
位置符号化と注意機構
Vaswani et al.の原論文では正弦波と余弦波を異なる周波数で組み合わせた位置符号化が採用されていた。一方、Su et al.が2021年に導入した回転位置埋め込み(RoPE)は、LLaMA、Mistral、Gemma、Qwen、およびその他のほぼすべてのオープンウェイトモデルファミリーで採用されている。RoPEは相対位置を自然に符号化すると言われており、実際の利点があると報告されている。
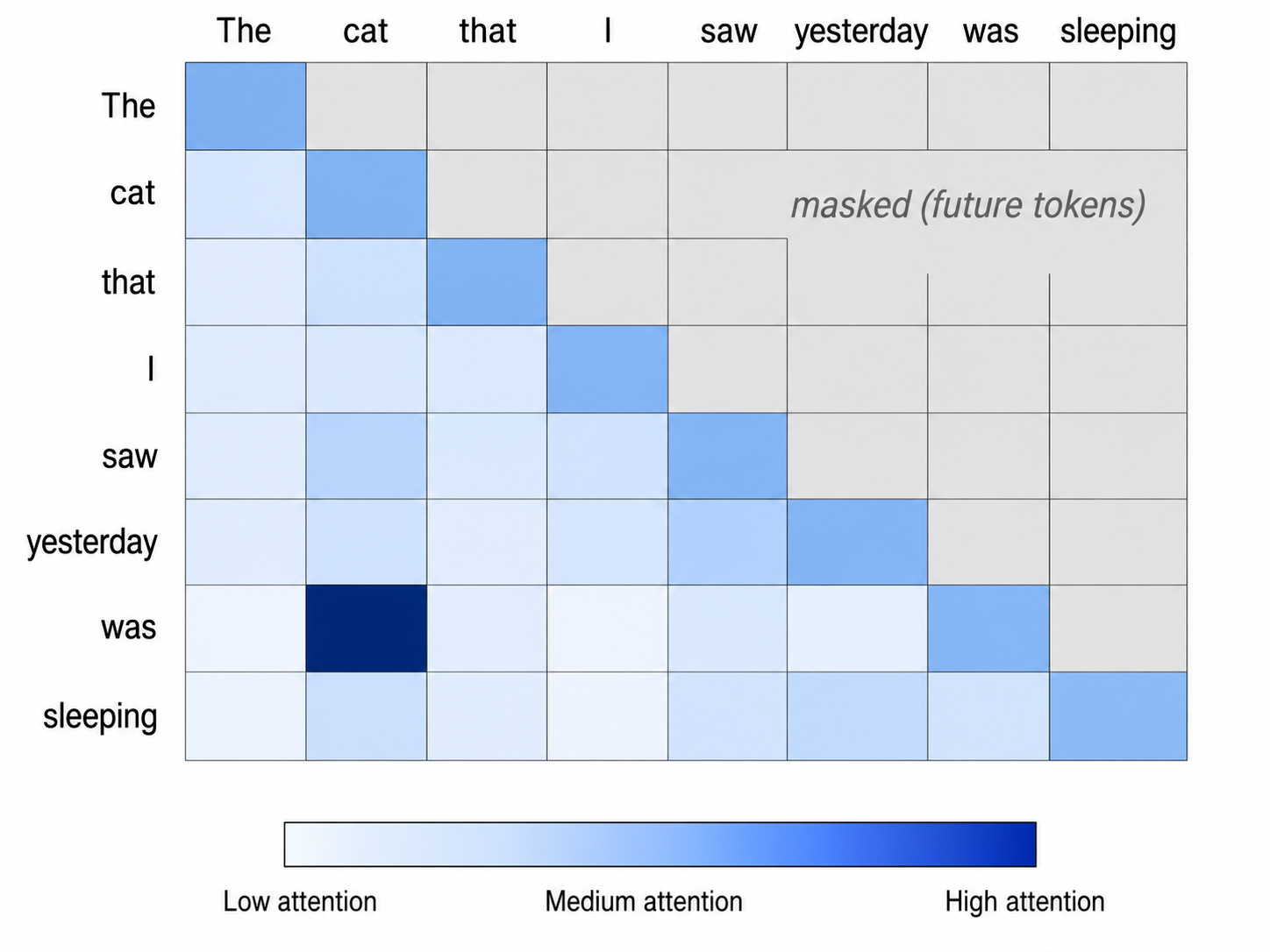
注意機構では、典型的なトランスフォーマーレイヤーは32の注意ヘッドを備えており、4,096次元の隠れサイズを持つモデルでは、各ヘッドあたり128次元の空間が割り当てられる。LLaMA-2 70Bは64のクエリヘッドに対して8つのキー・バリューヘッドのみを有し、Mistral 7Bは32のクエリヘッドと8つのキー・バリューヘッドを備えている。LLMには、長いプロンプトの中間部分よりも開始部分と終了部分の情報をより確実に利用する「lost in the middle」問題が知られており、Liu et al.が2023年に研究している。
フィードフォワードネットワークとパラメータ配置
原論文のトランスフォーマーはReLUを使用していたが、GPTとBERTはGELUに移行し、LLaMA、Mistral、PaLMなどの現代的なモデルではSwiGLUが使用されている。密なトランスフォーマーモデルのほとんどのパラメータはフィードフォワードネットワーク(FFN)に存在し、注意メカニズムには存在しない。また、Mixtral 8x7Bはレイヤーあたり8つの専門家を備え、各トークンに対して2つのみが活性化される構造を採用している。総パラメータ数は46.7億であるが、トークンあたりのアクティブ化パラメータは12.9億である。
正規化と残差接続
元の2017年のトランスフォーマーは各サブブロック後に正規化を適用する(ポスト正規化)していたが、GPT-2以降、LLaMA、Mistralではそれぞれのサブブロック前に正規化を適用する(プレ正規化)が一般的である。LLaMA、Mistral、Gemma、Phiを含む多くの現代的なオープンモデルはRMSNormを使用している。残差接続がなければ深いモデルの学習は格段に難しくなり、層正規化がなければ累積和が拡大または崩壊する可能性があるとされている。
トークン予測
生成時に次の単語を予測するため、モデルは最後のトークンの最終ベクトルのみを取得する。語彙が100,000トークンである場合、この最終ベクトルはロジットと呼ばれる100,000個の数値に変換される。
この記事は元記事の事実のみに基づいて自動生成されました。
筆者の見立て
- トランスフォーマーの仕組みを理解することがLLMの動作理解の大部分を説明するという解釈を示唆している
- 埋め込み空間の幾何学的性質が本来的な意味構造を持つこと、及びこれがモデルに明示的に指示されていないにもかかわらず生成されることを論じている
- 埋め込みに対する算術演算がしばしば機能することを意見として提示している
- トークナイザーの選択が計算量と多言語対応に影響することを示唆している
- LLM間の相違は学習データ、スケール・構成の選択、およびポストトレーニングから生じるという解釈を示唆している
- 注意ヘッドの特化が明示的な指示なしに学習中に自然に出現することを論じている
出典
0xkato「How LLMs Actually Work」https://www.0xkato.xyz/how-llms-actually-work/(Vaswani et al. 2017、Liu et al. 2023、He et al. 2015 の報道による)