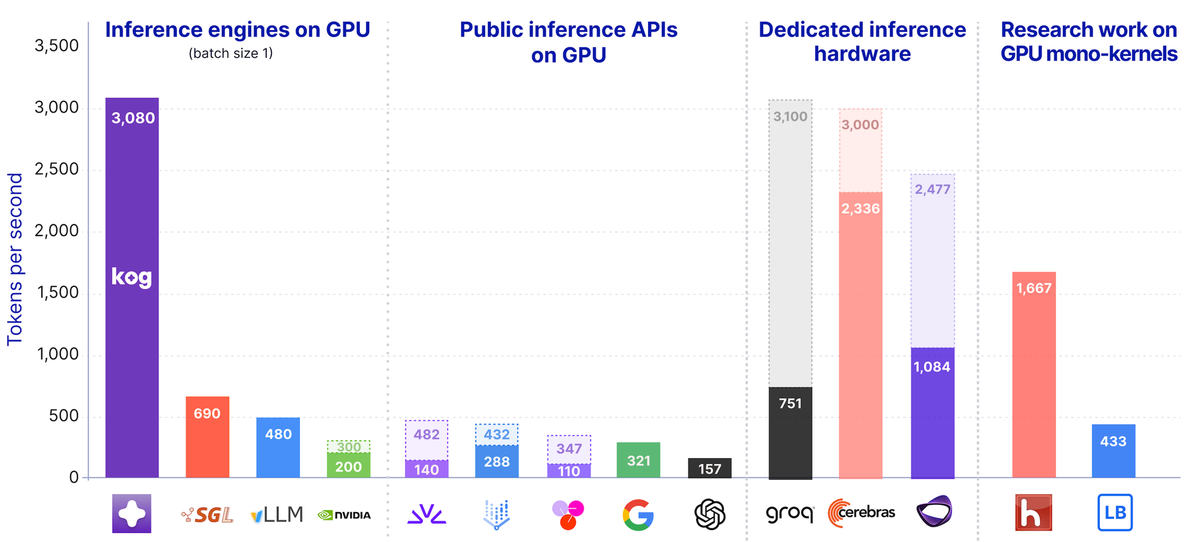
標準GPUで毎秒3,000トークンを実現――Kog AIが推論エンジンを発表
Kog AIは2026年5月28日、単一リクエストあたり毎秒3,000トークンの出力を実現する推論エンジンのテックプレビューを発表した。8枚のAMD MI300X GPUで3,000トークン/秒、8枚のNVIDIA H200で2,100トークン/秒(FP16、推測デコーディングなし)を達成している。
パリを拠点とするKog AIが発表した「Kog Inference Engine(KIE)」は、メモリ帯域幅の最大化と単一リクエストデコーディングの最適化を実現した。テックプレビューは2Bパラメータモデルで動作し、大規模なMoEモデルへの対応は近日予定されている。テスト環境は playground.kog.ai で利用可能である。
推論エンジンの技術構成
Kog Inference Engine は モノカーネル型の永続GPU プログラム、最適化されたGPUコード、Delayed Tensor Parallelismを備えたLaneformer モデルアーキテクチャを組み合わせて実装されている。単一リクエスト生成速度は自律型AIエージェントにおいて重要であり、メモリ帯域幅がボトルネックとなることが明らかにされている。
8枚のNVIDIA H200ノードは実効aggregate メモリ帯域幅30.7 TB/sを提供し、8枚のAMD MI300X ノードは約33.6 TB/s に達する。Kog のKCCL通信プリミティブはAllReduceレイテンシを3マイクロ秒以下に実現し、MI300X上のバリアレイテンシは位相認識最適化後に約600ナノ秒である。
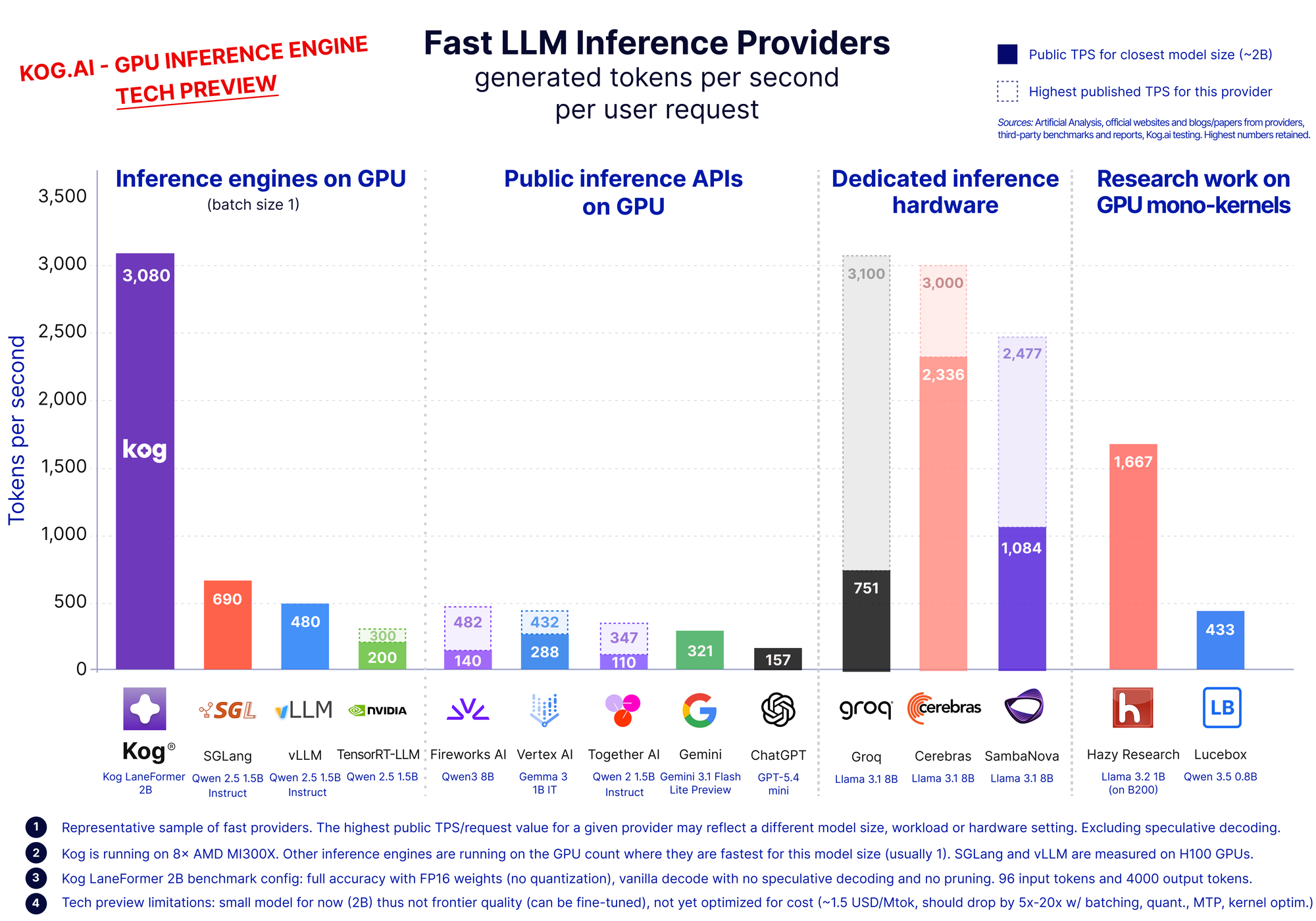
Laneformer 2Bモデルの性能
テックプレビューに搭載されるLaneformer 2B モデルはHumanEval コーディングベンチマークで50%のスコアを達成した。比較として、Qwen2.5-Coder 1.5B は43.9%、Qwen2.5-Coder 3B は52.4%である。このモデルはNVIDIA Nemotron v1 およびv2 データセット上で6T トークンの事前学習を受け、256個のH100 GPU クラスタで学習された。コンテキストウィンドウは4096シーケンスで、128k への長コンテキスト拡張が目標とされている。
企業背景と資金調達
Kog は2023年にGaël Delalleau によって設立された。2026年5月時点で、同社はVarsity VC およびBPI France Deep Tech Program から500万ドルの資金調達を完了している。2025年10月にはフランステック2030ラベルの認定を受けた。チームは11名で構成され、エンジニア・研究者10名を含む。うち5名はPhD保有者である。
筆者の見立て
- エージェントがより自律的になるにつれて、生産性の限界線が「知能のみ」から「知能 × 反復速度」へシフトしているとの解釈を示唆している
- 最良のエージェントは同じ経過時間内でより多くの有用なトークンを生成し、より多くの推論、ツール呼び出し、テスト、修正を実行すると予想している
- 毎秒100トークンと毎秒3,000トークンの差は構築可能なプロダクトそのものを変えるとの解釈を示唆している
- 利用可能なHBM帯域幅の増加とKogスタック成熟に伴い、大規模フロンティアMoEモデルの単一リクエスト生成速度が標準的なデータセンターGPU上で毎秒1,000〜5,000トークン帯域に移行すると予想している
- 専用推論ハードウェアが単一リクエスト生成速度を独立したインフラストラクチャカテゴリとして確立し、自律型AIエージェントの台頭とともにますます重要になると予想している
この記事は元記事の事実のみに基づいて自動生成されました。
出典
Kog Labs「Real-time LLM Inference on Standard Datacenter GPUs (3,000 tokens/s per request)」https://blog.kog.ai/real-time-llm-inference-on-standard-datacenter-gpus-3-000-tokens-s-per-request/